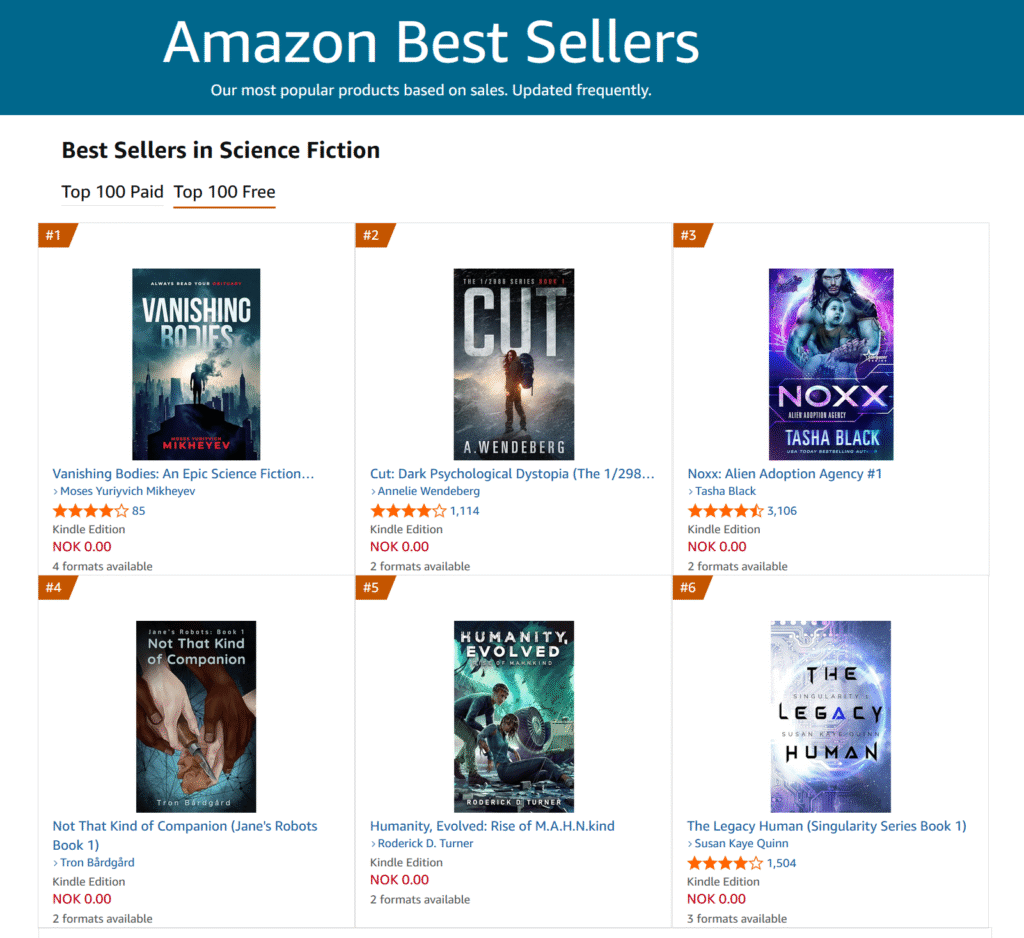
Reading text aloud is an excellent tool for revision work. At least for me, it has helped smooth out a lot of rough patches and catch a fair number of typos. For my first book, I used ElevenLabs and paid about 100 dollars for an AI audiobook generation of the manuscript while it was still under revision.
But AI has developed quite a bit since then, and with Google Gemini 3.1 Flash TTS, the audio quality has improved a lot. It adds some emotion to the reading by default, and more can be added by using extra tags in the text, such as [curious].

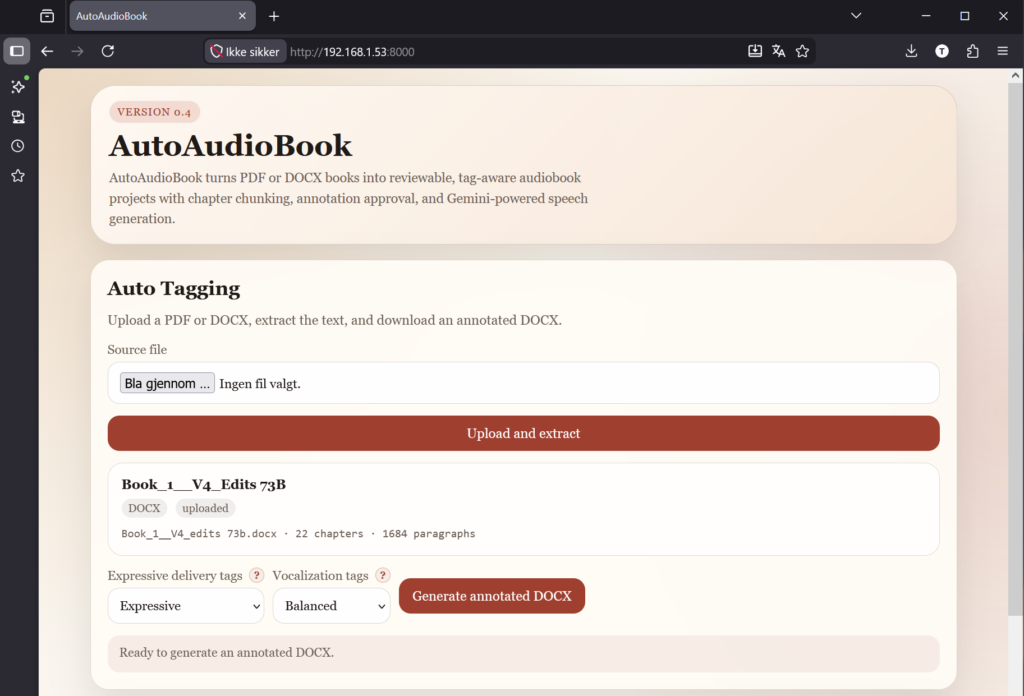
The problem is that tagging a document takes time, and the new Gemini TTS model has problems with long passages. So I started developing a tool that I could install on a virtual machine.

I set it up running on my small NAS, a Beelink Me Pro. Combined with a Gemini API key, automatically tag a document, generate read-aloud chunks, and merge these into chapter-length MP3s for download. The API price for the same book that cost 100 dollars a year ago is now closer to 10 dollars.
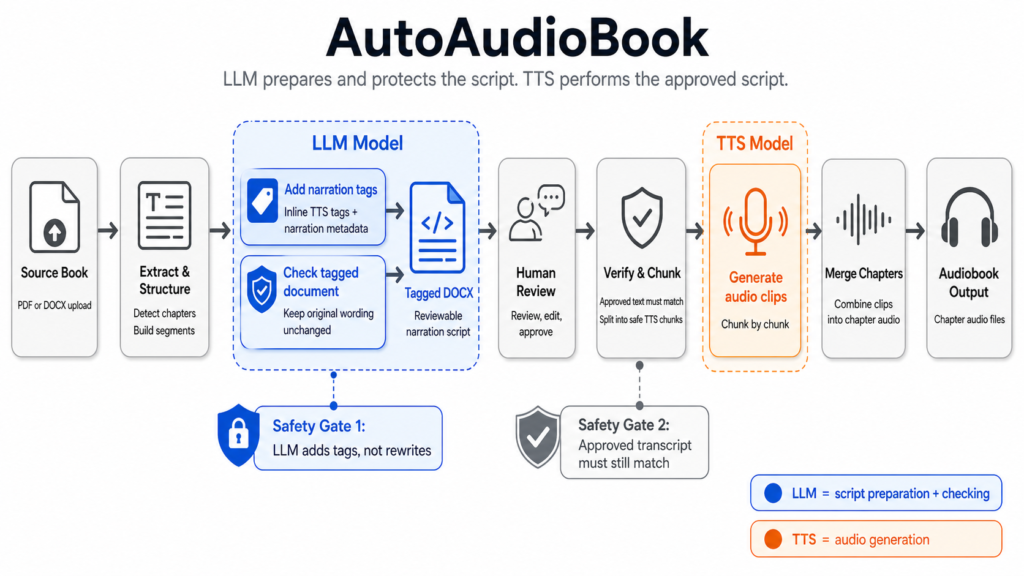
A key feature of this system is that it can easily be controlled by a agentsystem like OpenClaw, allowing it to make audio clips of the section of text I will work with next. That way, it’s possible to automate some boring tasks while allowing me to focus on writing and revising my text.
Speech synthesis is a double-edged sword when it comes to literature. Narrators’ jobs might dry up, and even if TTS audio becomes very good over time, having another person involved with the narration is still something different from using an AI. But I would not have a person narrate my beta text. It would cost too much, and it would not be a good use of someone’s time. This is one place where I think AI can be useful without being harmful.
You can read more about this project on the project’s GitHub. I also added a short audio example generated by the tool.